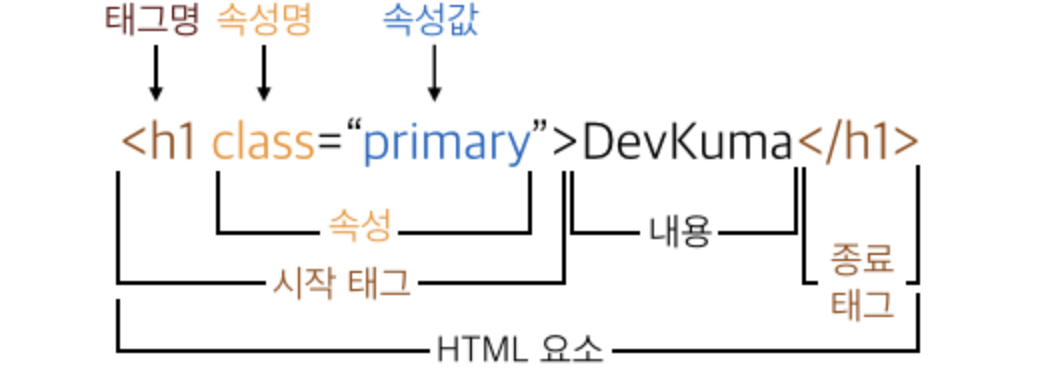
scrapy 대규모 데이터 수집을 위한 패키지 라이브러리
0. scrapy - 대규모 데이터 수집을 위한 패키지 라이브러리
: scrapy는 데이터 수집에 최적화된 라이브러리로 페이지를 크롤링하고, url 다운로드 및 파싱하고, 데이터를 저장하는 과정 일련이 모든 과정이 한꺼번에 처리가 올인원 라이브러리이다. scrapy의 기본적인 사용 방법부터 알아보고 그 안에 있는 기능들을 다루는 세부 내용을 차례로 정리해보자.
1. scrapy 설치 및 기본 사용법
1) scrapy 라이브러리 설치
: 터미널 혹은 cmd 개발 환경에서 아래 명령으로 scrapy 라이브러리 설치
- pip install scrapy
2) scrapy 프로젝트 구성
: scrapy 프로젝트를 진행하고자 하는 경로로 이동한 후 신규 폴더를 생성한 뒤 프로젝트를 시작하기 위한 명령어를 기입한다. (예시로 scrapyproject2 활용)
- 입력 내용 : scrapy startproject <프로젝트명>
- 실제 입력 : scrapy startproject scrapyproject2
: 위와 같이 입력하면 폴더가 생성된다. 터미널에서 폴더 경로를 따라 폴더명(위에서 지정한)으로 2회 이동한다. 해당 위치에서 pwd 명령어 (현재 위치) ls 명령어 (현재 경로에 위치한 파일/폴더 리스트 확인)를 확인하면 아래와 같이 세팅되어 있음을 확인 가능하다.

: 해당 위치에서 크롤링 페이지를 지정하기 위해 아래의 명령어를 입력해야 한다. (예시로 gmarket 페이지를 진행)
- 입력 내용 : scrapy genspider <크롤러 이름> <크롤러 페이지 주소>
- 실제 입력 : scrapy genspider gmarket_best corners.gmarket.co.kr/Bestsellers
# 크롤러 이름 : 크롤링 프로젝트 내에 여러 가지 크롤러 (scrapy에서는 spider) 있을 수 있으므로, 각 크롤러의 이름을 지정
# 크롤링페이지 주소: 각 크롤러가 크롤링을 시작할 페이지를 주소로 지정
# 주소 입력 간에 'https://' 부분은 빼고 입력하는 것이 좋음 (중복 발생)
: 위의 작업이 완료될 시에 spiders 폴더 내에 ls 명령 시 해당 크롤러가 설치되었음을 확인 가능하다.

3) 해당 프로젝트 컴파일러에서 확인
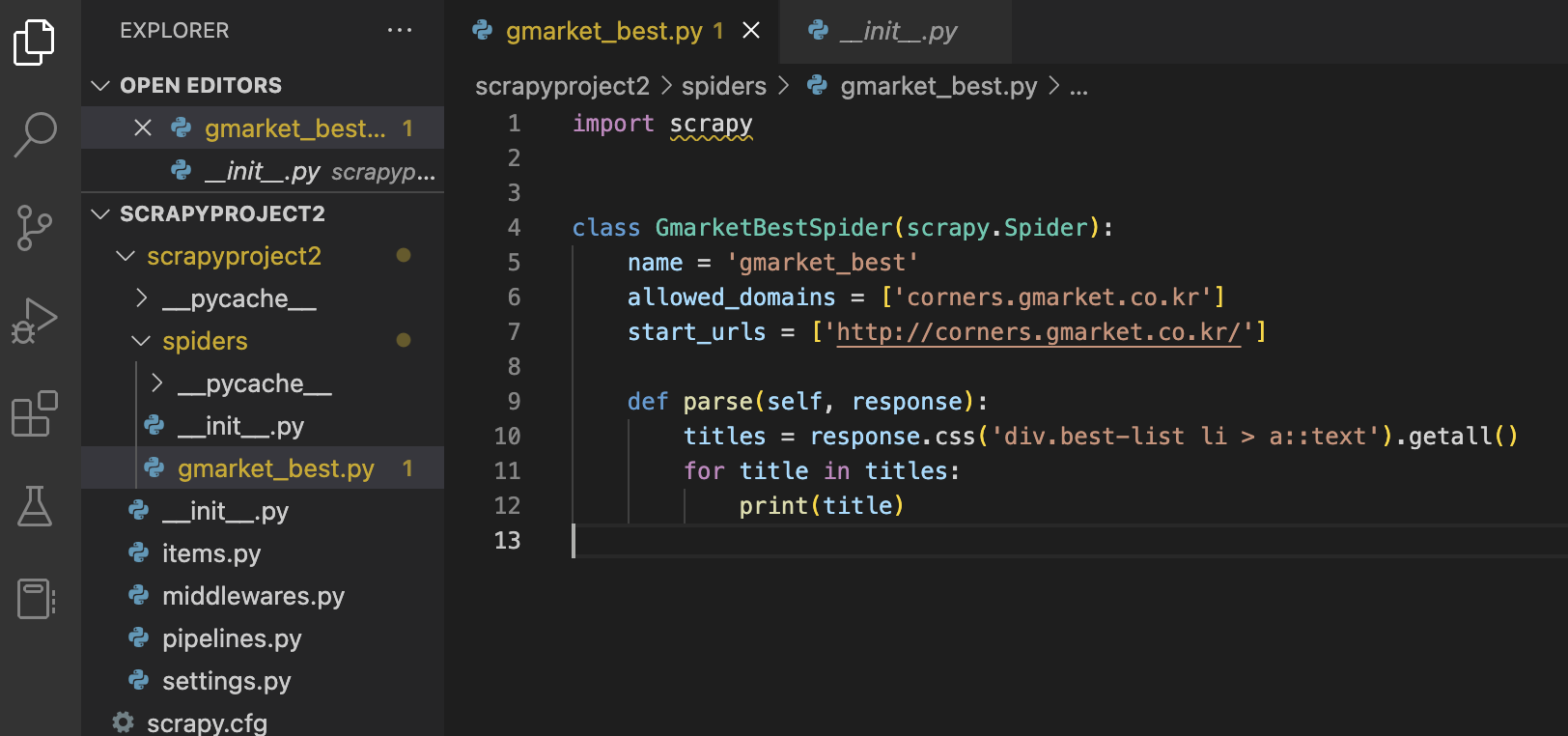
: 해당 폴더를 컴파일러(sublime text3 / atom/ vs code)에서 키면 아래와 같이 기본 세팅되어 있음을 알 수 있다.

4) 데이터 추출 및 추출 양식에 대한 작업 진행
: gmarket best 페이지 내 상품명을 추출하는 상황을 가정하여 CSS selector를 활용해 추출하는 구문을 작성했다. 기본 구문 외의 추가적인 기능 (itme/ pipilines/ setting 등 타 페이지 활용법)은 다른 페이지에서 정리하고자 한다.
5) 터미널에서 명령어 실행
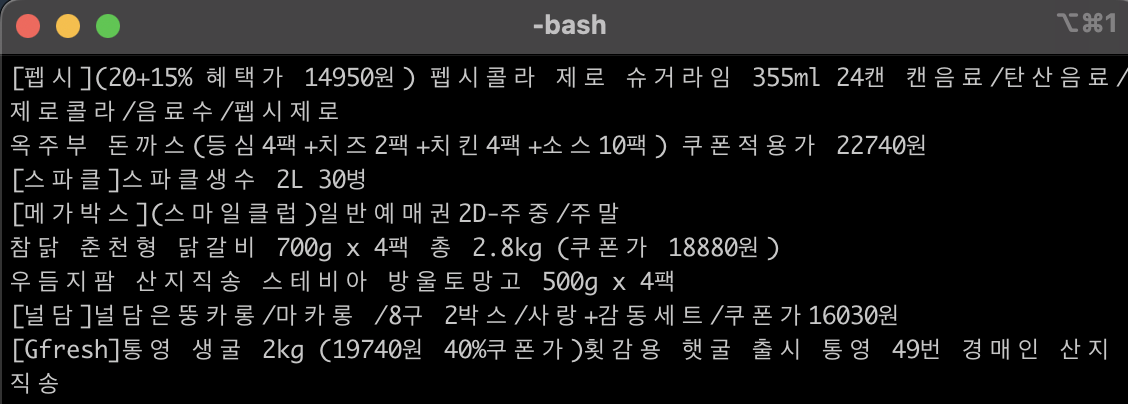
: pwd 명령어(현재 경로 확인) 통해 프로젝트명으로 2번 이동한 경로에서 genspider을 통해 생성한 크롤러 이름을 입력하면 해당 VS코드에 작업한 명령어가 실행됨을 확인할 수 있다.
- pwd

- 입력 내용 : scrapy crawl <크롤러명>
- 실제 입력 : scrapy crawl gmarket_best
'python > python_crawling' 카테고리의 다른 글
| [파이썬] selenium 동적 조작 기능 정리 (0) | 2023.01.02 |
|---|---|
| [파이썬] selenium 기본 사용법 정리 (0) | 2023.01.02 |
| [파이썬] BeautifulSoup find와 select 함수 사용법 정리 (0) | 2022.12.28 |
| [파이썬] BeautifulSoup 기본 사용법 정리 (0) | 2022.12.27 |
| [파이썬] Scrapy, Selenium, BeautifulSoup 장단점 비교 (0) | 2022.12.27 |