BeautifulSoup - 초보 사용자를 위한 가장 간편한 라이브러리
0. BeautifulSoup find와 select 함수 이해
: BeautifulSoup 라이브러리를 통해 HTML 형태로 가공한 웹페이지 데이터 상에 필요한 정보를 특정하기 위해 추가적으로 함수 사용이 필요한데, 이때 사용되는 대표적인 함수 두 가지가 find와 select 함수이다. 기본적인 HTML, CSS 구조를 이해하고 find와 select 함수가 각각 어떻게 쓰이는지 정리해보고자 한다.
✓ find 함수와 select 함수 사용법 및 결론 요약
: find 함수와 select 함수 중 select 함수 사용에 익숙해지는 것이 더 좋다. find와 select는 모두 태그명, 속성, 속성값을 활용하는 방식이지만, CSS는 보통 여러개의 선택자 (Selector)를 갖고 있기 때문에 태그를 특정하기 위해선 일반적으로 여러 요소(element)를 함께 조합해야 한다. 이때 경로를 지정하는 방식과 관련하여 find는 함수를 여러번 반복하여 코드를 작성해야 하는 반면 select는 하나의 함수 내에 직접 하위 경로를 지정할 수 있는 기능이 존재하기 때문이다.
1) find 함수 사용법 - 아래 기본 구조 중 선택해 사용
- data = soup.find('태그명')
- data = soup.find('태그명', class_ = 'class 값')
- data = soup.find('태그명', 'class 값')
- data = soup.find(id = 'id값')
- data = soup.find('태그명', attrs = {'속성 이름' : '속성 값'})
1) select 함수 사용법 - 아래 기본 구조를 조합해 사용
- data = soup.select('태그명')
- data = soup.select('.클래스값')
- data = soup.select('#id값')
- data = soup.select('상위태그' '자식태그')
- data = soup.select('상위태그' > '자식태그')
- data = soup.select_one('id값')[속성]
1. HTML과 CSS의 기본 구조 이해
: BeautifulSoup는 물론 앞으로 Selenium이나 Scrapy 같은 정보 추출을 위한 라이브러리를 활용하기 위해 우선적으로 HTML과 CSS 구조에 대해 이해해야 한다. 특히 하나의 요소 안에 담긴 속성명과 속성값의 개념을 이해하는 것과 태그 간의 관계성에 기반한 상위태그 자식태그의 개념 두 가지만 우선적으로 알아보자.
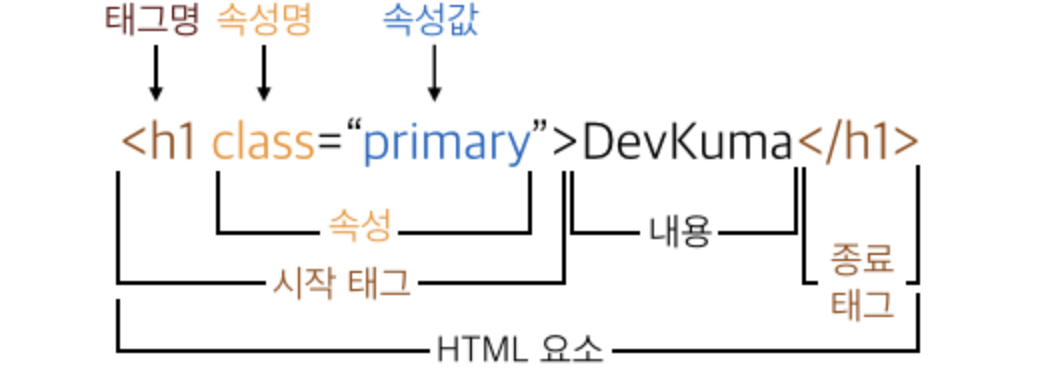
1. HTML 요소의 기본 구조
: HTML의 요소는 <시작태그>로 시작해 </종료태그>로 끝나는 하나의 구문을 말하며, 여러개의 속성을 가질 수 있다는 특징이 있다. (속성은 해당 태그에 추가적인 정보들을 담고 있다.) 우리가 일반적으로 추출하고자 하는 정보는 태그 사이에 있는 내용(아래 이미지 참고)에 위치해 있는 경우가 많아 태그명은 물론 속성명과 속성값에 대해 활용할 수 있어야 한다. 대표적으로 많이 사용되는 두 가지 속성 'Class'와 'Id'의 경우 별도의 표현 방식을 통해 해당 요소를 특정할 수 있어 데이터 추출 간 좋은 힌트가 될 수 있다.
2. 부모 태그와 자식 태그의 관계
: HTML은 요소들은 기본적으로 부모 자식 관계 혹은 형제 관계로 구분된다. 원하는 정보가 위치한 태그안에 해당 태그를 특정할 만한 속성 정보가 부족할 때, 해당 태그의 부모 태그까지 함께 이용하는 것이 가능하기 때문에 크롤링 과정에서 부모태그의 개념을 이해하는 것이 매우 중요하다. 부모 자식 관계는 들여쓰기 형태로 구분되어 있어 HTML 구문을 직접 보면서 바로 확인이 가능하다. 아래를 예시로 부모 자식 관계를 부등호 표시로, 형제 관계를 등호 표시로 표현해보자면 html > body > h1 = div > span = img 와 같이 정리 가능하다.

2. select 함수와 find 함수 사용법
✓ 활용 예제 : span 태그 내의 '상품명' 정보 추출하기
from bs4 import BeautifulSoup
html = """
<html>
<body>
<h1 id='head'>구좌명</h1>
<div class='item'>
<span class='title' id='first'> 상품명1 </span>
<img class='main' id='first_img' src='이미지주소' width='50px'>
</div>
<div class='item'>
<span class='title' id='first'> 상품명2 </span>
<img class='main' id='first_img' src='이미지주소' width='50px'>
</div>
</body>
</html>
"""
soup = BeautifulSoup(html,"html.parser")1. find 함수를 활용한 정보 추출
: find 함수는 조건에 부합하는 태그 중에 가장 먼저 발견되는 하나의 값을 가져다 준다. (print로 출력) 또한 조건 간의 중복적으로 사용할 수 없기 때문에 하나의 함수에 조건만 추가할 수 있다. 만약 부모태그 정보를 넣고 싶다면 find 함수 자체를 여러번 사용해야 하는 불편함이 있을 수 있다.
1) find 함수를 사용해 정보 추출하기
- 태그명을 이용해 정보 추출하는 방법

- 태그명 + 클래스 값을 이용해 정보 추출하는 방법


- 아이디 값을 이용해 정보 추출하는 방법

- data = soup.find('태그명', attrs = {'속성 이름' :'속성 값'})

2) find_all 함수를 사용해 조건에 부합하는 모든 값 추출하기 (for반복문 통해 출력)

3) find 함수 중복 사용을 이용한 부모 태그 정보 기입하기

2. select 함수를 활용한 정보 추출
: select 함수는 조건에 부합하는 모든 태그의 값을 리스트 형태로 반환한다. (for 반복문으로 출력) 또한 조건 간의 중복사용이 가능하기에 하나의 함수에 여러 조건을 함께 쓸 수 있다. 부모태그 정보도 함께 기입할 수 있는 기능이 있어 활용성이 find 함수에 비해 상대적으로 높다.
1) select 함수를 사용해 정보 추출하기
: 하나의 요소(element) 안에 놓인 태그명/ 클래스 값/ id 값을 띄어쓰기 없이 연속으로 적어 데이터 특정이 가능하다. 다만 작성간 아래 조건에 따라 각 속성들을 추가해야 한다.
- data = soup.select('태그명')
- data = soup.select('.클래스값')
- data = soup.select('#id값')

2) select_one 함수를 사용해 정보 추출하기
: select_one 함수는 find 함수와 맞찬가지로 조건에 부합되는 값들 중 가장 먼저 발견되는 값을 가져와 print로 출력 가능하다

: select_one 함수를 활용하면 요소 안에 들어있는 내용뿐만 아니라 속성값 출력도 가능하다.
- data = soup.select_one('id값')[속성]

3) select 함수 이용한 부모 태그 정보 기입하기
: select 함수는 단일 태그의 정보를 조합적으로 이용할 수 있으며 동시에 부모 태그 혹은 부모의 부모 태그 (그 이상까지도..) 하나의 함수로 직접 활용이 가능하다. 부모태그에 대해 띄어쓰기를 통해 표시하면 되지만 바로 앞에 위치한 부모태그의 경우 부등호 ('>') 표시를 통해 보다 정확하게 정보 표시가 가능하다.
- data = soup.select('상위태그' '자식태그')
- data = soup.select('상위태그' > '자식태그')

'python > python_crawling' 카테고리의 다른 글
| [파이썬] selenium 동적 조작 기능 정리 (0) | 2023.01.02 |
|---|---|
| [파이썬] selenium 기본 사용법 정리 (0) | 2023.01.02 |
| [파이썬] BeautifulSoup 기본 사용법 정리 (0) | 2022.12.27 |
| [파이썬] Scrapy, Selenium, BeautifulSoup 장단점 비교 (0) | 2022.12.27 |
| [파이썬] openpyxl 라이브러리 활용한 엑셀 파일 추출 (0) | 2022.12.16 |