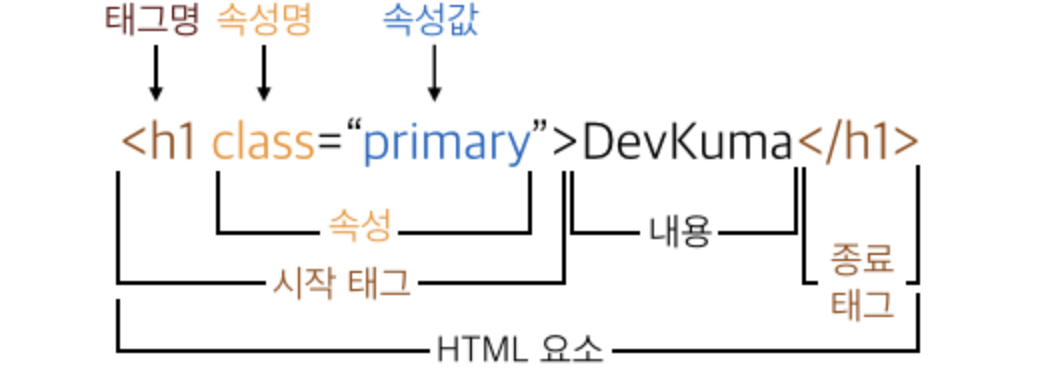
SQL 기본 문법 이해 (CRUD)
1. SQL 기본 문법 (CRUD)의 개념과 쓰임 정리
CRUD는 대부분의 컴퓨터 소프트웨어가 가지는 기본적인 데이터 처리 기능인 Create(생성), Read(읽기), Update(갱신), Delete(삭제)를 묶어서 일컫는 말이다. SQL 정보를 조작하는 데 있어 CRUD는 기본적으로 쓰이는 명령어로 그 쓰임과 사용 방법에 대해 알아야 한다.
| CRUD | 조작 | SQL |
| Create | 생성 | INSERT INTO 테이블명 VALUES 값 |
| Read(또는 Retrieve) | 읽기(또는 인출) | SELECT 값 FROM 테이블명 |
| Update | 갱신 | UPDATE 테이블명 SET 수정할 컬럼명 = '수정값' |
| Delete(또는 Destroy) | 삭제(또는 파괴) | DELETE FROM 테이블명 WHERE 조건 |
1. 데이터 생성 (CREATE)
1) 테이블 전체에 대응하는 값을 모두 넣는 경우
INSERT INTO 테이블명 VALUES(값1, 값2, 값3, ...);2) 테이블 특정 컬럼에 대응하는 값만 넣는 경우
INSERT INTO 테이블명 (컬럼1, 컬럼2, 컬럼3, ...) VALUES (값1, 값2, 값3, ...);2. 데이터 읽기 (READ)
1) 테이블 전체 컬럼의 데이터 모두 읽기
SELECT * FROM 테이블명;2) 테이블 특정 컬럼의 데이터만 읽기
SELECT 컬럼1, 컬럼2 FROM 테이블명;3) 테이블 특정 컬럼의 데이터를 검색하되 표시할 컬럼명도 다르게 하기
SELECT 키존컬럼이름 AS 바꿀컬럼이름 FROM 테이블명;4) 조건에 맞는 데이터만 검색하기
- WHERE 조건문으로 조건 검색
- 논리연산자 (AND, OR) 사용 가능
SELECT * FROM 테이블명 WHERE 컬럼1 < 5 or 컬럼2 < 10- LIKE 통해 부분적으로 일치 데이터 추출 가능
- 개수와 상관 없이 모두 찾을 경우 '%' 한번 사용
- 특정 개수 만큼 다른 경우를 찾을 경우 '_' 해당 글자수만큼 사용
SELECT * FROM 테이블명 WHERE 컬럼1 LIKE '홍%'
SELECT * FROM 테이블명 WHERE 컬럼1 LIKE '홍___'5) 데이터 정렬해서 읽기
- ORDER BY 정렬할 컬럼명 DESC 혹은 ASC
- DESC는 내림차순 ASC는 오름차순
SELECT * FROM 테이블명 ORDER BY DESC
SELECT * FROM 테이블명 ORDER BY ASC6) 결과 중 일부만 데이터 가져오기
- LIMIT N; : 첫 행부터 N개 추출
- LIMIT N M; : N행부터 M개 추출
SELECT * FROM 테이블명 LIMIT 100, 3;
3. 데이터 수정 (UPDATE)
1) 보통 WHERE 조건문과 함께 쓰여 특정한 조건에 맞는 데이터만 수정하는 것이 일반적인 사용법
UPDATE 테이블명 SET 수정할 컬럼명 = '수정할 컬럼값' WHERE 특정 칼럼 = '값';2) 특정 조건에 따라 변하는 컬럼 값을 다수 설정 가능
UPDATE 테이블명 SET 수정할 컬럼명1 = '수정할 컬럼값1', 수정할 컬럼명2 = '수정할 컬럼값2' WHERE 특정 칼럼 = '값';4. 데이터 삭제 (DELETE)
1) 보통 WHERE 조건문과 함께 쓰여서, 특정한 조건에 맞는 데이터만 삭제하는 경우가 많음
DELETE FROM 테이블명 WHERE 특정 컬럼 = '값';2) 테이블에 지정된 모든 데이터를 삭제할 수도 있음 (하지만 기본적으로 기능 제한되어 있음)
DELETE FROM 테이블명;'SQL' 카테고리의 다른 글
| [SQL] MYSQL 데이터 타입 종류와 특징 (0) | 2023.01.17 |
|---|---|
| [SQL] 데이터베이스 및 테이블 기본 조작어 (0) | 2023.01.11 |
| [SQL] SQL 관련 기본 개념 정리 (0) | 2023.01.10 |