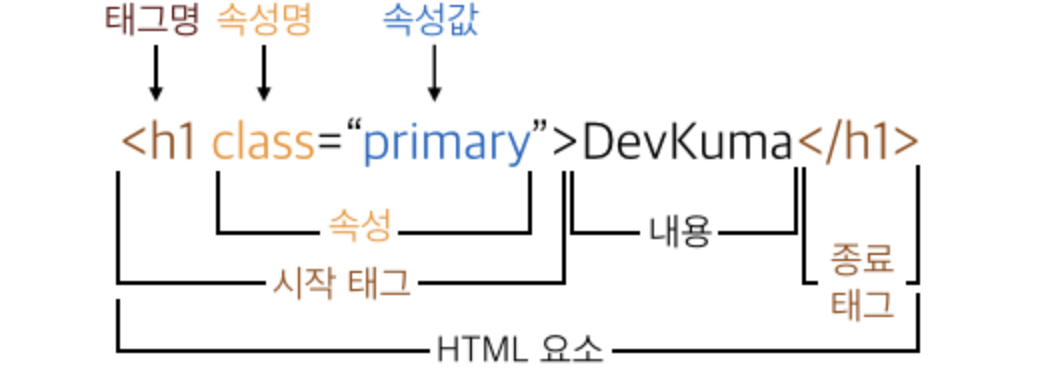
시리즈(Series)와 데이터프레임(DataFrame)에 대한 이해
0. 판다스(pandas)의 기본 자료 구조
판다스는 R을 모티브로하여 만든 파이썬 라이브러리이다. 데이터 분석을 위해 수집, 전처리 등의 과정은 대부분 데이터프레임의 형태로 이루어지는 경우가 많은데 여기서 데이터 프레임이란 엑셀에서 흔히 볼 수 있는 행과 열로 이루어진 표를 의미한다.시리즈는 데이터 프레임의 하위 자료형으로 1개의 열로만 구성된 자료구조를 의미한다. 여러 개의 시리즈가 모여 데이터프레임을 형성한다고 이해하면 쉽다.
- 시리즈(Series) : 한 개의 열과 인덱스로 구성된 1차원 데이터 구조
- 데이터프레임(DataFrame) : 다수의 시리즈가 있는 행과 열로 구성된 테이블형(2차원) 데이터 구조
1. 시리즈(Series) 조작어 정리
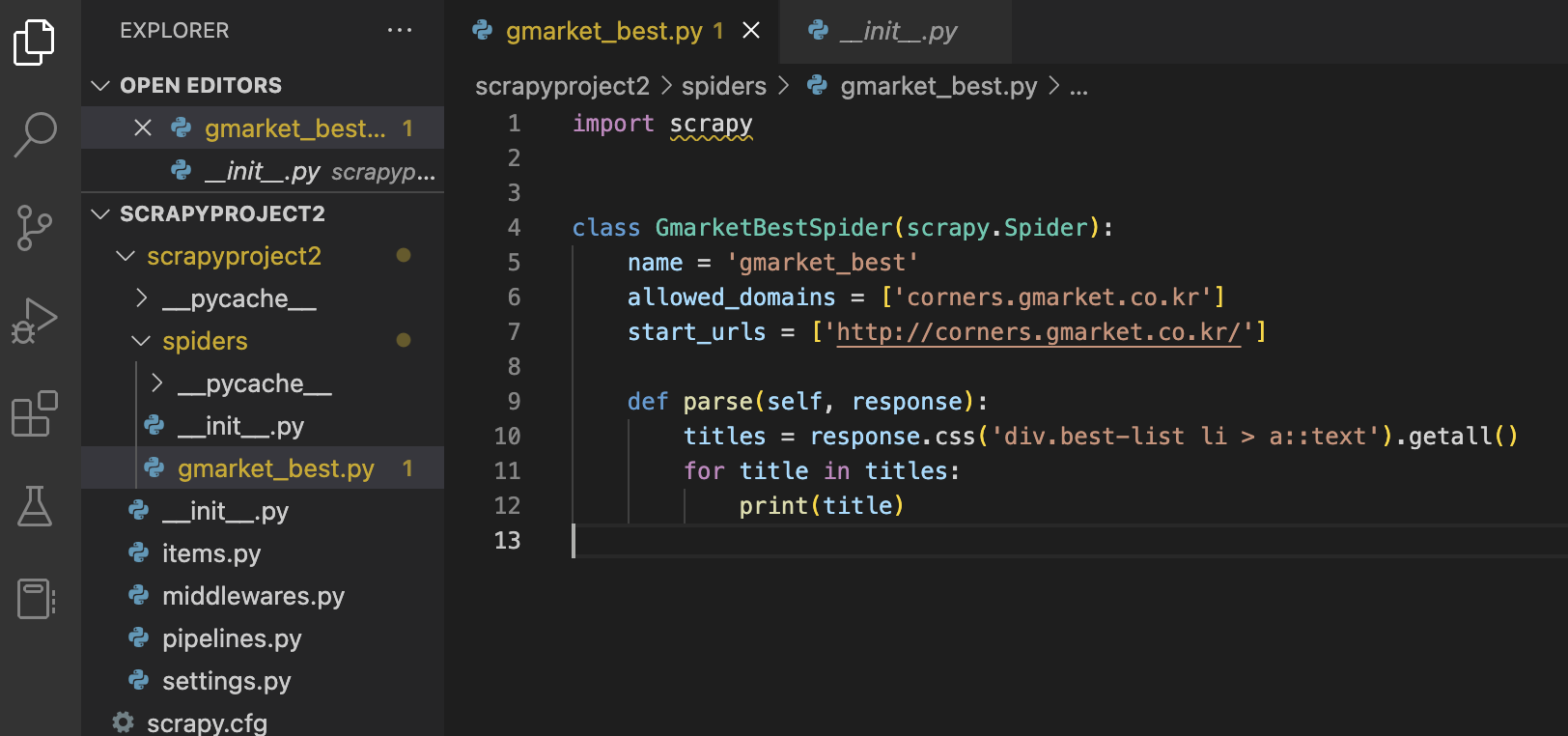
1. Series 생성 (CREATE)
- Series 자료구조는 리스트 혹은 딕셔너리를 통해 생성이 가능하다.
- 리스트로 생성할 경우 index는 생략 가능하며 생략 시에는 0,1,2,3 으로 자동 기입된다.
- 리스트를 통해 Series 생성
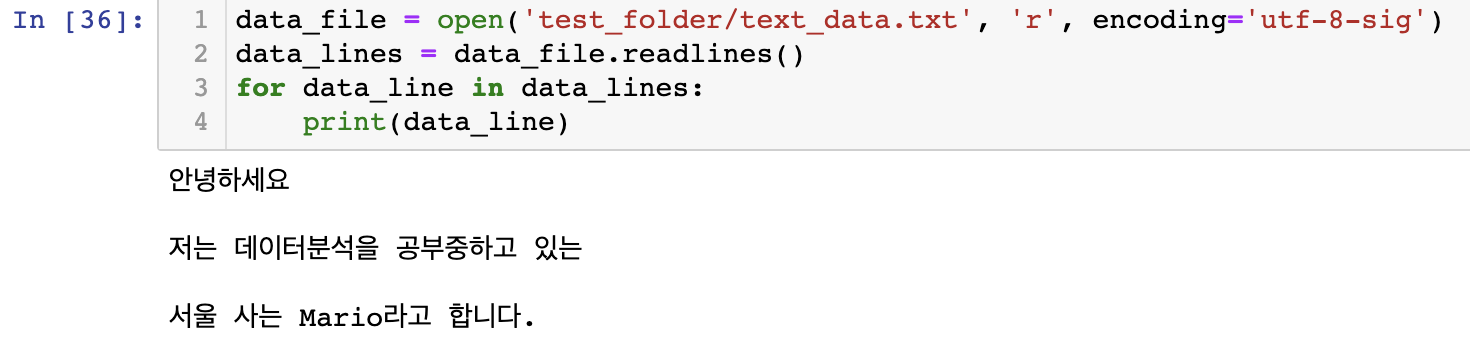
import pandas as pd
data = pd.Series(['value1','value2','value3'], index = ['index1','index2','index3'])
- 딕셔너리를 통해 Series 생성
import pandas as pd
data = {'index1'='value1','index2'='value2','index3'='value3'}
Series_data = pd.Series(data)
- Series 조작어 연습 위한 테스트 예제

2. Series 데이터 읽기 및 수정 (Read&Update)
2-1) Series 내 index 관련 조작어
- index 읽기

- index 수정

2-2) Series 내 values 관련 조작어
- Values 읽기

- Values 수정
- values는 values = [ ] 형태로 직접 수정이 안 되며 인덱스를 통해 수정해야 한다.

3. Series 데이터 삭제 (Delete)

2. 데이터프레임(DataFrame) 조작어 정리
1) DataFrame 생성(Create)
- DataFrame 생성 코드
df = pd.DataFrame({
'column1': ['value1','value2','value3'],
'column2': ['value1','value2','value3'],
'column3': ['value1','value2','value3']},
index = ['index1','index2','index3']
)
- DataFrame 조작어 연습 위한 테스트 예제

2) DataFrame 데이터 읽기 및 수정 (Read & Update)
2-1)DataFrame 내 index 관련 조작어
- index 읽기

- index 내용 수정하기

- index 컬럼 새로 지정하기

- index 컬럼 지정 내용 원복하기

2-2)DataFrame 내 Column 관련 조작어
- column 읽기

- column 내용 수정하기
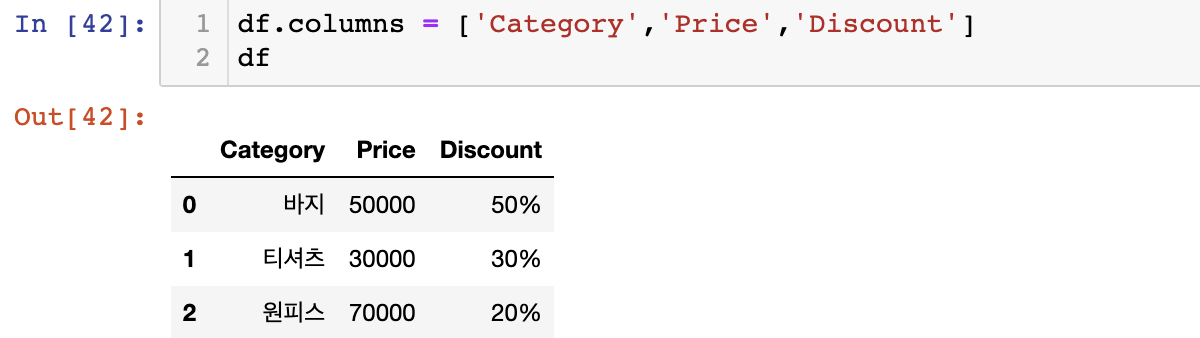
- column 신규 항목 추가하기

- column 특정 항목 제거하기

2-3)DataFrame 내 values 관련 조작어 : ioc와 lioc
- 데이터프레임.loc : index를 통해서 값을 찾음
- 데이터프레임.iloc : 인덱스 번호를 통해서 값을 찾음 (0부터 시작)
- 특정 행 읽기 : loc로 특정 행 찾기

- 특정 행 읽기 : iloc로 인덱싱

- 특정 열 읽기

- 특정 값 찾기
- 특정 행에 컬럼 값 추가

- 특정 열에 인덱스 값 추가

- 신규 행 추가하기

'python > python_시각화' 카테고리의 다른 글
| [파이썬] 파이썬으로 Plain Text 포맷 파일 다루기 (0) | 2023.02.01 |
|---|